|
Xiquan Li 李希泉 I am a dual-degree master's student at Shanghai Jiao Tong University and Télécom Paris, advised by Prof. Xie Chen at X-LANCE Lab, SJTU and Prof. Slim Essid at ADASP Group, Télécom Paris. Currently, I am interning at ByteDance Seed, working on multimodal understanding and generation. Previously, I received my bachelor's degree from Shanghai Jiao Tong University in 2024. During that summer, I was a research assistant at The Chinese University of Hong Kong (CUHK), working with Prof. Qiuqiang Kong at the DSP Lab, CUHK. I have also interned at Tencent Hunyuan Team. |

|
Research Interests
My primary research interest lies in audio understanding and generation. I aim to build intelligent audio systems that can:
I'm currently seeking PhD / industrial opportunities for 2027! |
News
[June 2026] Resonate has been accepeted by Interspeech 2026.
|
Selected Publications |
|
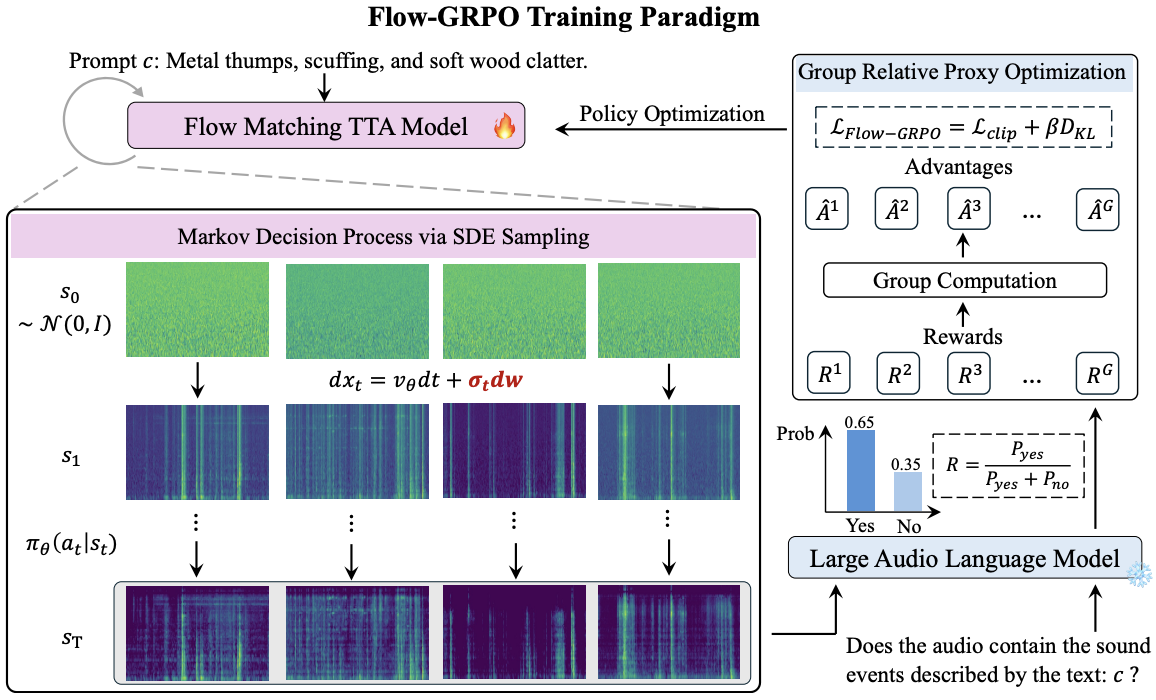
Resonate: Reinforcing Text-to-Audio Generation via Online Feedback from Large Audio Language Models
Xiquan Li, Junxi Liu, Wenxi Chen, Haina Zhu, Ziyang Ma, Xie Chen Interspeech, 2026 paper / code / demo A flow-matching-based text-to-audio model enhanced with online RL via GRPO. |
|
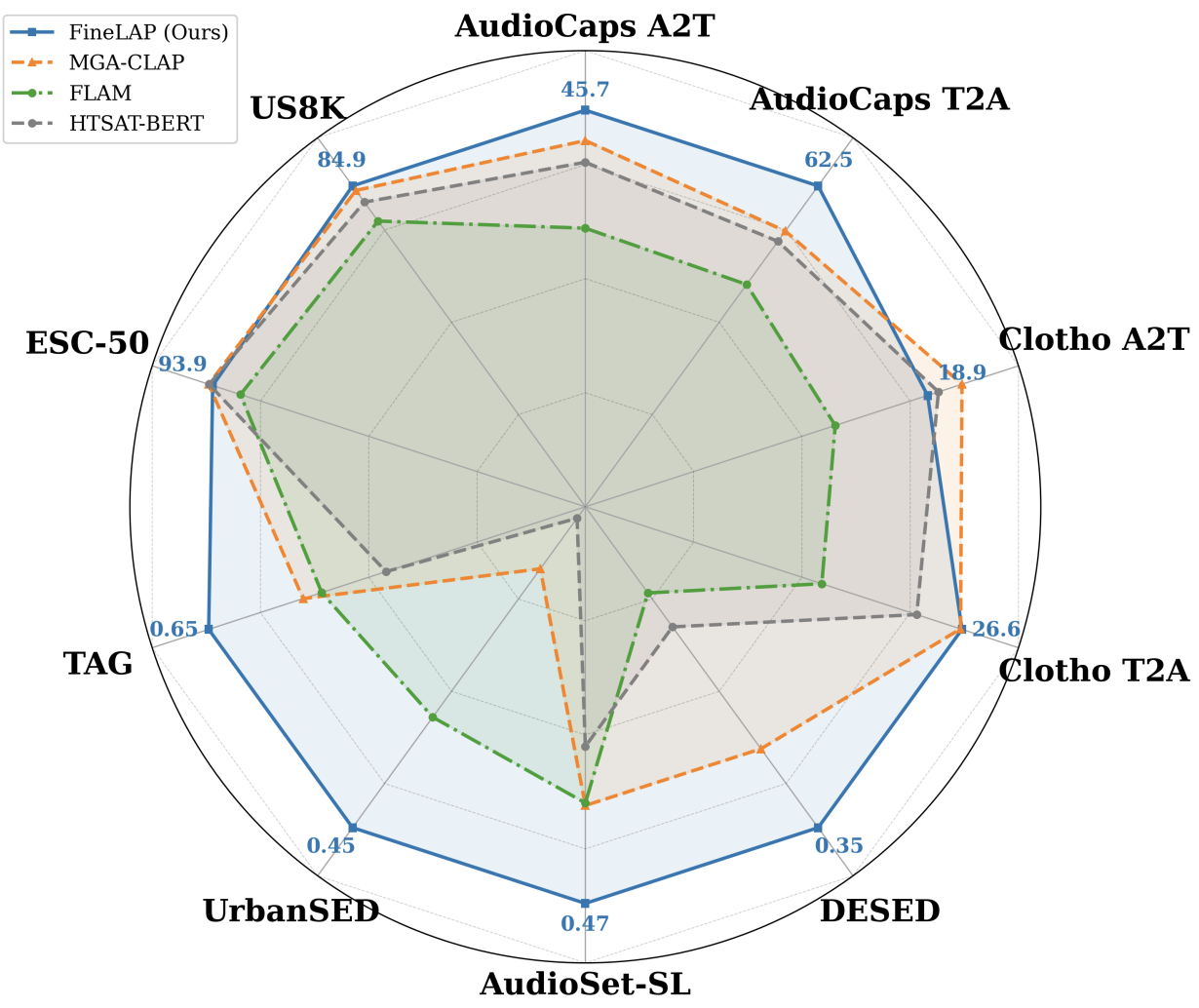
FineLAP: Taming Heterogeneous Supervision for Fine-grained Language-Audio Pretraining
Xiquan Li, Xuenan Xu, Ziyang Ma, Wenxi Chen, Haolin He, Qiuqiang Kong, Xie Chen ACL, 2026 (Main) paper / code / dataset A contrastively pretrained audio-language model that excels at both clip- and frame-level audio understanding tasks. |
|
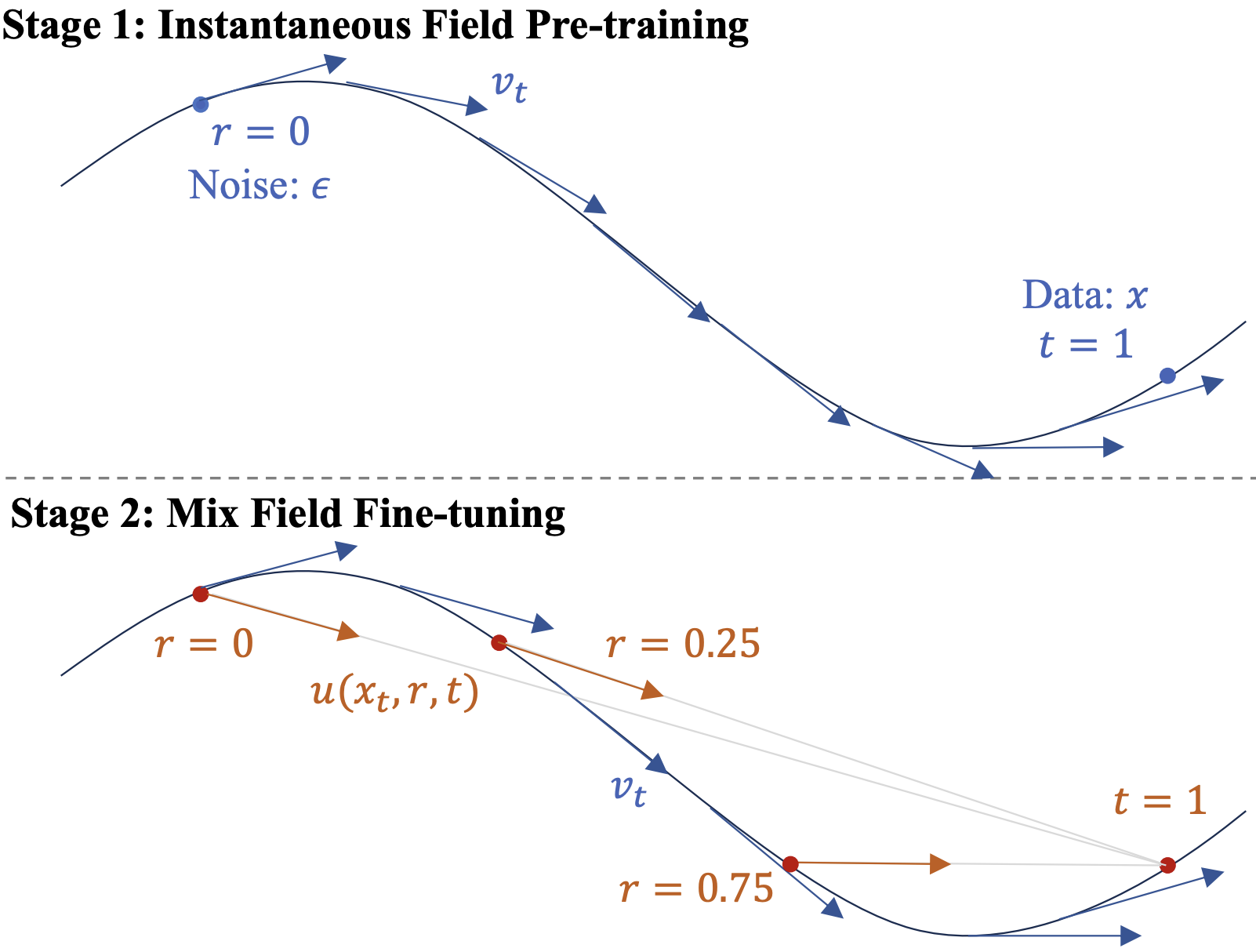
MeanAudio: Fast and Faithful Text-to-Audio Generation with Mean Flows
Xiquan Li*, Junxi Liu*, Yuzhe Liang, Zhikang Niu, Wenxi Chen, Xie Chen ACL, 2026 (Main) paper / code / demo A fast and faithful text-to-audio generator that incorporates MeanFlow for single-step synthesis. |
|
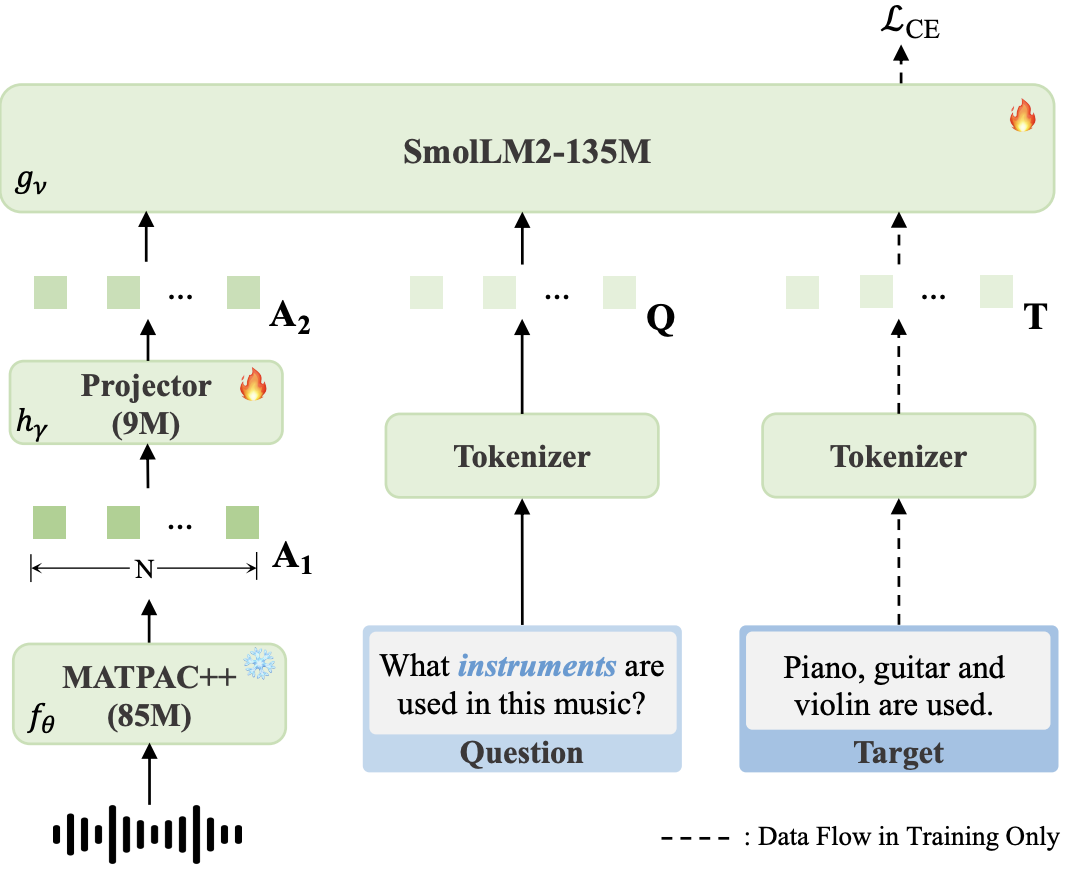
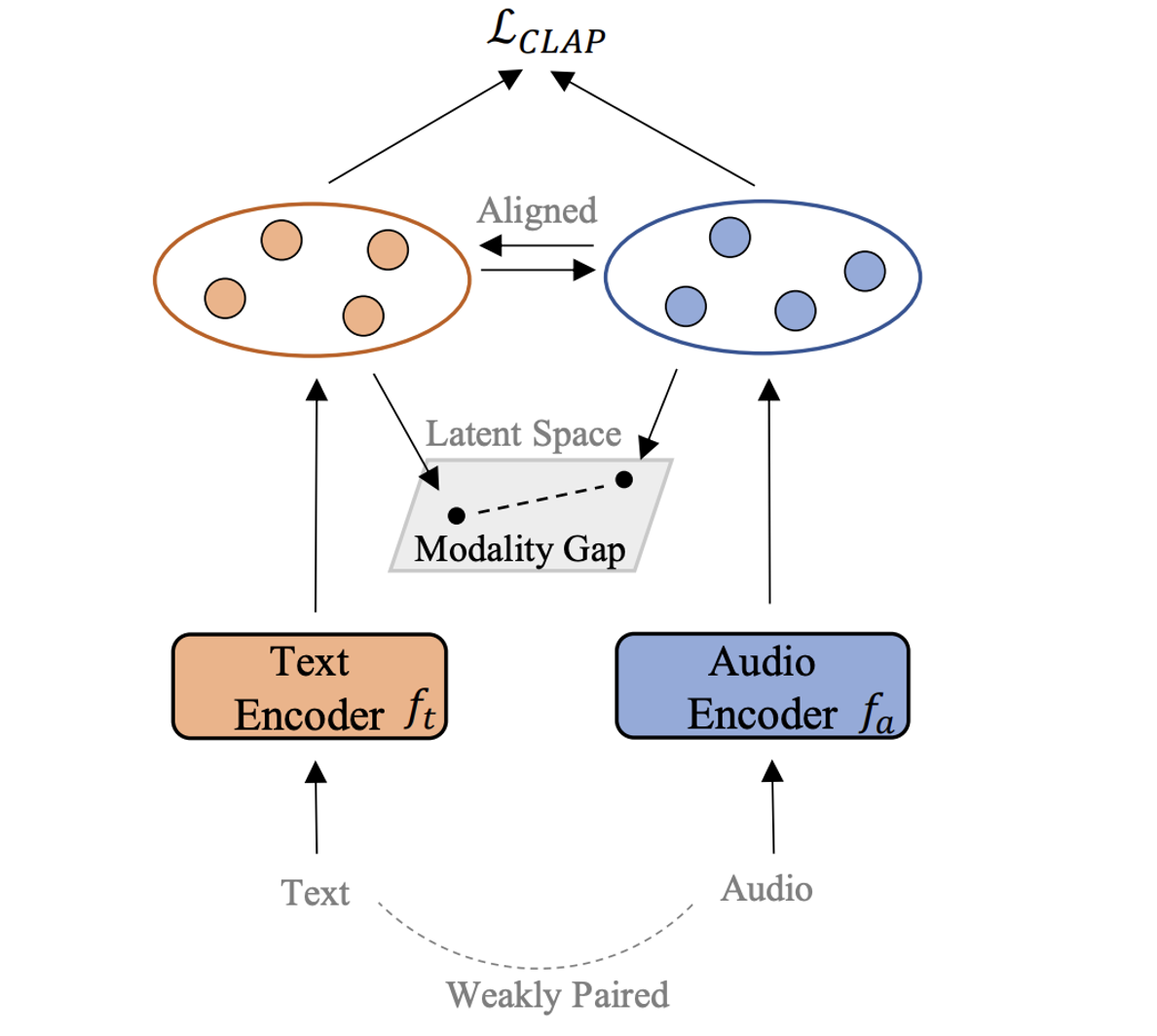
TinyMU: A compact Audio-Language Model For Music Understanding
Xiquan Li, Aurian Quelennec, Slim Essid ICASSP, 2026 paper / code / dataset A compact audio-language model with strong music understanding and reasoning ability. |
|
DRCap: Decoding CLAP Latents with Retrieval-Augmented Generation for Zero-shot Audio Captioning
Xiquan Li, Wenxi Chen, Ziyang Ma, Xuenan Xu, Yuzhe Liang, Zhisheng Zheng, Qiuqiang Kong, Xie Chen ICASSP, 2025 (Oral) paper / code A zero-shot audio captioning system with strong in-domain and cross-domain performance. |
Education |
|
Shanghai Jiao Tong University, Shanghai, China
M.E. in Information Engineering, Sep. 2024 - Mar. 2027 |
|
|
Telecom Paris, Palaiseau, France
M.E. in Information Engineering, Sep. 2023 - Jun. 2026 |

|
|
Shanghai Jiao Tong University, Shanghai, China
B.E. in Information Engineering, Dual Degree in French, Sep. 2020 - Jun. 2024 |
|
Experience |
|
Seed Speech Group, ByteDance, Shanghai, China
Intern, Nov. 2025 - Present |

|
|
Hunyuan Team, Tencent, Shanghai, China
Intern, Jun. 2025 - Nov. 2025 |

|
|
ADASP Group, Telecom Paris, Palaiseau, France
Research Intern, Sep. 2024 - Jun. 2025 Advisor: Slim Essid |
|
|
DSP Lab, The Chinese University of Hong Kong, Hong Kong, China
Research Assistant, Jun. 2024 - Sep. 2024 Advisor: Qiuqiang Kong |
|
|
X-LANCE Lab, Shanghai Jiao Tong University, Shanghai, China
Research Intern, Jan. 2023 - Present Advisor: Xie Chen |
|
MiscApart from research, I enjoy skiing, playing soccer, and working out. Check out some of the wonderful ski moments here :) |
|
|
|
Updated April 2026 Template adapted from Here |